Wells Fargo
Todd Nichols
Anser Enterprise
A White Paper presented at a HyPerformix User Conference
Introduction
Wells Fargo continues to grow its customer base by offering innovative, high-value products as well as through mergers with other recognized financial institutions. To this end, Wells has established itself as a technology leader in electronic banking and Internet Banking by internally developing and maintaining IT systems, which are scalable, extensible and adaptable to increasingly demanding market conditions. These systems need to continue to meet Wells Fargo's high standards for responsiveness, availability and security while at the same time offer good return on IT investments.
To help insure continued high performance with increased complexity, Wells Fargo is augmenting its existing performance measurement, monitoring and analysis capabilities with predictive performance modeling capabilities. Over the last ten months, Wells has pursued feasibility testing of tools and techniques for hardware and software characterization and modeling. Wells has increased its familiarity with discrete event simulation modeling techniques using SES Strategizer as well as application profiling, application source code review, data visualization and Web performance documentation techniques. Wells is making the necessary investments to gain long term returns by focusing on methodologies that favorably impact related performance activities including capacity planning and application architecture and design.
Wells Fargo Enterprise Performance Management (EPM), a performance group within Wells Fargo Technology Services, has embraced the philosophy that integrating performance modeling into application development life-cycle processes is key to making enterprise system modeling a cost and time-effective strategy. Wells Fargo Technology Services feels that enlisting the active participation of the benefactors of performance modeling (Wells Fargo business organizations) is a key to its success. This paper describes techniques and procedures currently under investigation to make this plan a reality based on the unique culture and experiences of Wells Fargo.
Current Project Status
Wells Fargo has completed the initial phases of integrating performance modeling into its other performance analysis and development processes. Although we see integration with capacity planning as a critical step, the bulk of our efforts to date have been on other fronts. Therefore, ours is very much an application-centric model at this point.
Internet Banking is the initial focus of our modeling work. Wells Fargo Internet Banking is a multi-tiered implementation of Web servers, object-oriented middleware and mainframe-based systems of record handling hundreds of thousands of on-line transactions by its customers.
Wells Fargo has a lot of things going for it to meet its goal of including discrete event simulation modeling into its development and other enterprise performance management processes. These include:
· A commitment to predictive performance engineering at all levels within Wells Fargo Technology Services organization,
· A team of talented performance analysts focused on end-to-end performance measurement and analysis,
· Oracle database and Perl programming expertise dedicated to building performance data-mining systems, and
· Internal technically innovative and supportive developer communities.
Wells Fargo, as a technology leader among financial institutions, is also fortunate to have the necessary IT infrastructure in place to implement our vision of a process-oriented approach to modeling. Components of this infrastructure include:
· Internally designed and developed banking applications with re-usable distributed object architecture,
· Flexible functional test harnesses easily modifiable for application profiling,
· Production management systems for reporting and tracking change management,
· Flexible Clearcase revision-control of source software allowing separate performance branches,
· Extensive intranet documentation produced by Wells Fargo organizations on all facets of banking operations,
· Systems integration group working with systems vendors, consultants and technical out-sourcing companies.
· Capacity planning group projecting hardware needs based on platform-based analytic modeling techniques
Wells Fargo
We worked primarily with these Wells Fargo groups with the following responsibilities:
·
Wells
· Networking - Develops firewall components including the interior and exterior routing hosts, inbound and outbound proxy servers, DNS Servers and Web home page servers. Others in the networking group are responsible for maintaining all of the routers and LANs and the Wells Fargo OpenNet - T1 and T3 connections linking the data centers and other parts of the bank.
· On Line Financial Services (OFS) - Develops Internet banking web server platform, CGI and Internet banking session processes.
· Business Object Services (BOS) - Develops CORBA distributed-object middleware servers that encapsulate the Systems of Record (SOR) on mainframes and UNIX/Informix databases. These business-object servers support call center and ATM applications as well as Internet Banking and provide a powerful enabling infrastructure for systems integration resulting from mergers.
· Production Services Division - Manages data center operations maintaining the SOR mainframes. Other than UNIX/Informix databases, all Systems of Record are hosted on mainframes. These were not modeled beyond the use of a simple Strategizer Delay statement. No database modeling was done.
Wells Fargo
This is a brief summary of the Wells Internet Banking systems described in the context of our modeling effort. For additional descriptions, see the published Client-Server text and ORB case study references [3][4]. The figure below was cut and pasted from the Strategizer Network Topology editor. It is a much-simplified version of our Wells Fargo Internet Banking model and is reduced to its primary components. To achieve scalability as is done in the actual Wells architecture (which also requires redundancy), these basic components are cloned in the model multiple times with the addition of many more LANs, WANs, routers, and an additional data center or two.
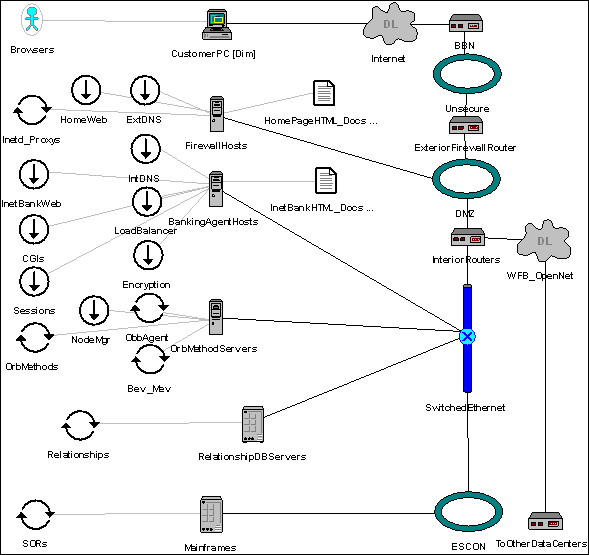
In the figure, Internet banking transactions originate at the top with the customer browsers and flow down to the Systems of Record on the mainframes at the bottom. The left-most column of circular Strategizer icons represents the processes that a transaction needing account information would minimally traverse. The other processes shown are very frequently involved as well. The platform icons in the center of the topology model show the multiple tiers of the architecture. The platforms are easily configured within Strategizer's GUI to run particular processes by making the light-gray line connections from the processes to the platforms. In the actual architecture and the full model, some of the platforms within categories of servers are dedicated to running particular processes. Looking down the next column showing the location of data, we see two file icons. The HTML files are not shared among servers in a tier using network file systems for security reasons. Strategizer database icons are not included indicating a lack of database modeling at this point. The two right-most columns in the figure show a few of the many network components in our model. The complete architecture in this figure is duplicated for another data center and is connected through what is shown as a Wells Fargo's OpenNet router.
Architectural Component Descriptions and Modeling Considerations
· External browser client workloads originate across Internet components. However, there is currently no detailed characterization of ISP delays or capacity. Client behaviors model Wells home page and Internet banking access including checks for browser type, sign-on, account summary retrieval, and sign-off. HTTP redirects and refreshes are modeled. Wells uses test browser clients located inside the firewalls that report on the contributions of Wells internal systems to expected customer response times. These reports are useful for validating the model. We started from but have substantially modified browser client behaviors found in Stategizer's web sample application.
· Wells home page web servers reside in the Wells firewall or DMZ area. These web server processes mainly reply to HTTP GET requests for static, non-secured pages for which we use the Strategizer web sample application. One HTTP POST request, which the home page web servers do service is a check of the client's browser type. We implement a Startegizer Startup process statement and execution times for this CGI.
· External and internal DNS servers map host name aliases to Wells IP addresses. In addition to incurring CPU execution delays, they are significant in our modeling because they are another source of routing configuration as in the case of DNS round-robin lists. Striving to duplicate actual production response times, we found that we need to account for a variety of configuration files for many processes.
· Proxy processes relay HTTP requests through the firewall to web server processes on banking agent hosts. It was necessary to model a separate UNIX inetd process, which spawns a separate proxy process for each web request. Here too, we needed to configure the model using source-to-destination routings and time-out values for failed socket connections found in proxy configuration files. A number of parameters passed through the Strategizer Receive statement in the proxy process contain information needed further in the model such as the target banking agent host and session id.
· Web server processes on banking agent machines inside the firewall (labeled InetBankWeb above) spawn CGI processes that link the web front-end to the mainframe data (SORs). They also reply to HTTP GET requests for static HTML pages and their embedded GIF images. We modified the Strategizer sample web application substantially by replacing threads with web "helper" processes, thereby separating the message queues to which both the browsers and replying CGI processes send messages. Also, we added finite queuing for TCP connections and Startup process statements for the CGIs.
· Sign-On CGI processes send messages to load balancer processes to get recommendations for which banking agent machine to assign to a customer for the length of his/her Internet banking session. The load balancer reads its configuration file to determine which banking agents are available and their weighting factors. This short-lived Strategizer process uses another Startup statement to create a long-lived session process.
· Session CGI processes communicate HTML request name/pairs to the long-lived session process but are themselves relatively short-lived. As with the sign-on and session CGI processes, they read from configuration files to get orb context variables and other runtime conditions.
· Session processes remain alive as long as a customer is signed-in and maintain the state of a customer's session across multiple URL requests. Encrypted session id's are passed back and forth between the browser and web server and are used to get back into one of hundreds of session processes that can be running on a banking agent host. The session processes use orb client libraries to pass messages to business object server process running on the Orb Method server hosts. The session process uses a state machine to process transactions and can defer back-end retrieval tasks to quickly get status screens back to the browsers. In all, we needed to account for a lot of modeling-significant application logic and execution times in this process.
· BEA Objectbroker object location servers (ObbAgent) are contacted for most CORBA messaging and are single-threaded.
· Node Managers are Wells-developed processes that load balance banking agent CORBA requests across many Orb Method servers. We encountered another important configuration file containing weighting-factors based on the sizes of Orb method server hosts used for the load-balancing.
· Orb Method server processes implement the Wells business object model and service many methods on many business objects. These business objects encapsulate the semantics and application API of the mainframe systems of record. Developers expressed interest in using modeling to predict the optimal number of orb method processes to run on method server platforms and the effect of CORBA and TCP timeouts and retries on overall performance. A lot of modeling input parameters were added for this portion of the model.
· Business Event (BEV) and Method Event (MEV) servers log transaction events occurring on the banking agent machines and the Orb Method server platforms, respectively. These processes run on dedicated method server machines. We included execution times for event logging in our model. Also, we use the logged response times and sample counts for detailed validation of our model.
·
Relationship server processes service
authorization checks as to which banking operations are allowed over which
channels (Web, AOL,
· Systems of Record (SOR) are the mainframe applications serving customer information and performing banking transactions. Separate mainframe communication processes handle TCP socket and BEA Tuxedo RPC-level messages from the method servers. The effects of communication time-outs at this stage are under investigation and will be an important area of modeling in the future. Currently, simple Strategizer Delay statements are used in the mainframe behaviors based on mainframe application logging.
Performance Modeling Goals and Objectives
Wells Fargo has a number of goals for performance modeling. Some of these are as follows:
· Use outside modeling expertise, but focus on technology transfer to develop in-house modeling capabilities.
· Improve the performance of an existing production system. Internet Banking was a prime candidate because of its visibility for the bank and the importance of good performance.
· Initially minimize the impact on the Wells development community. Wells Fargo is in the process of merging with Norwest resulting in Wells West and Wells East. Interruptions of development activities for model building should be kept to a minimum.
· Ultimately integrate predictive modeling into development life-cycle processes, by getting developers directly involved in the modeling process.
· Build accurate models. With the decision to model actual production systems, it is important to be able to predict known conditions including response times. Establishing modeling credibility in light of the complexity of the system is a major goal.
· Build highly maintainable models. Changes and new production releases are constant. There was skepticism that the model could be kept up-to-date with the actual production systems.
Impetus for our Modeling Approach
The modeling approach proposed within Wells Fargo is based on an understanding of the company's situation and culture. We analyzed various possibilities for characterizing the applications and measuring execution times, which are described in the Appendix. We decided on an in-depth analysis of application source code along with application profiling to determine execution times. Apart from the modeling activity, the approach has proven beneficial to others for the better understanding it affords of systems under analysis. Documentation of application logic flows for model building is one example. Better representation of performance logging and points of serialization such as external encryption hardware are other experiences.
Modeling of proposed systems can be easier and produce even more immediate and larger payoffs than modeling existing production systems. Clearly, there will be fewer system details consuming modeler's time and energy where the system does not yet exist. Calibration of the model is not a requirement and accuracy is not measurable at this stage. In these cases, there are still opportunities to influence purchasing decisions for millions of dollars of hardware if the orders have not been placed and systems are not already installed. Strategizer is clearly within its element as a modeler/architect's tool for "what-if" analysis where there is a clean pallet. In these situations, one can make the case that modeling should be the domain of the modeling specialist with years of experience. There are no concrete guidelines or measures for creating models and expert judgement and mastery of statistical techniques is important.
One might ask, "If modeling a planned system is easier, less risky and with larger immediate payoffs, why should a company start with modeling a complex real-world system where purchasing and design decisions have already been made, many of which are hard or expensive to undo?". Three reasons come to mind:
1. Accurately predicting the performance of existing enterprise-wide production systems builds credibility in the modeling.
2. Building highly maintainable models of enterprise-wide production systems forces modelers to be less isolated by their specialization.
3. Getting modeling into the hands of developers as an integral part of the development process is more sustainable over the long term and can have a larger impact on an organization. Tools and techniques are needed to support modeling by non-specialists.
Modeling as Shared Perspective of Performance
Within Wells Fargo, Internet Banking spans four separate development organizations (as described above). A long term hope for the Wells end-to-end Strategizer performance modeling is to provide a common tool and perspective for the various groups to use to pinpoint performance problems. Such tool might be used to facilitate Wells’ performance meetings involving representatives from various groups. During these meetings, participants share their understandings of portions of the Internet Banking chain to help identify and solve performance bottlenecks. From a modeler's perspective, the expressions of participants' understandings in these meetings are in effect their own mental "models" of how their portion of the system works in relation of their mental "models" of the portions of other groups. Naturally, it is difficult to share and agree on the accuracy of mental models, especially when the analysis tends to shift the responsibility of highly visible performance problems from one group to another.
Within a single Wells development organization, our objective is to have developers build component models for their own piece of the overall application. An independent benchmarking group would have responsibility for actually testing application performance and certifying that the modeling components were accurate when compared to the benchmark results. Bringing these modeling components together to identify a specific performance problem seems to offer a way of providing objectivity and guarantees that a stake owner's portion of the chain will be analyzed in a quantitative and fair manner.
The following sections and figure offer a more formal statement of our goals and approach for modeling.
A Process Approach to Architectural and Capacity Planning Performance Modeling
Wells Enterprise Performance Management proposes to institute new processes and analysis capabilities that span Wells Internet Banking, including Networking, OFS (Online Financial Services), BOS (Business Object Services) architecture, design, implementation and capacity planning activities. Our predictive modeling is complementary to the existing Wells performance monitoring and management work. Existing approaches provide snapshots in real time of where performance bottlenecks are occurring, and provide the ability to make immediate operational changes based on that knowledge. On the other hand, performance modeling provides views into the future for where bottlenecks might occur and provides guidance in making architectural and/or hardware changes. Performance monitoring can also be used to initially calibrate and, on a continuous basis, validate the performance modeling capabilities. The new processes commission modelers, in concert with architects and developers, to develop libraries of models representing, in a performance sense, the business objects that developers produce along with their actual application code, test suites, and documentation. Wells EPM takes leadership to formulate and guide the new processes and participate in the modeling activity. However to be successful in the long-term, these skills need to be integrated with the existing development and capacity planning processes.
Current Business Situation and Requirements
End-to-end Internet Banking performance continues to be a major priority for Wells.
Wells capacity planners currently have predictive tools to plan for hardware system and software upgrades. As recommended by experts in performance analysis, Wells Enterprise Performance Management is complementing the use of analytical modeling tools (BEST/1) with discrete event simulation modeling tools (SES/Strategizer).
Wells developers spend time optimizing segments of application code without knowing how overall response times will be improved. As a guide, they need access to the same discrete event simulation tools and assistance to begin to model their applications.
In general, better insight into probable performance ROI is needed to help guide Wells choices. Wells needs these analysis capabilities internally. Vendors are not always in a position to have the complete understanding of Wells infrastructure and applications to make accurate sizing recommendations.
Shared Approach to Component Modeling
Performance modeling tools along with Wells EPM assistance in making measurements, building models and training, is part of the solution to meet Wells business needs.
Performance modeling allows capacity planners to ask questions such as, “What if we upgrade CPU’s, add memory, etc.? How would performance be affected?” These are systems issues. Performance modeling allows architects and developers to ask questions such as, “What if we multi-thread an existing application, distribute a database to another host, optimize segments of application code, etc.? How would performance improve?” These are application architecture issues. Both groups should contribute to the building and maintenance of performance models. Both groups will use and benefit from the performance modeling.
Development and Capacity Planning Process Components
Enterprise Performance Management plans over time to enhance software development processes that incorporate additional activities for modelers, in concert with developers. For example, as new designs or changes are being considered, modelers with developers should build modeling modules before applications are implemented. The models predict how the new or changed applications will perform in the complete Internet Banking environment. The processes will also define how measurements (not provided by existing performance management) are made after the application is actually built to determine execution path-lengths through the code. These measurements are used to accurately parameterize the modeling modules. The processes define how final modeling modules are to be released at the same times that the new application components are released. New modeling modules are certified to accurately represent the new application components and are then added to a growing library of Wells modeling components.
Enterprise Performance Management is developing hardware and network characterization processes that involve capacity planners. EPM could configure the modeling tool to automatically extract relevant Wells network topology from HP OpenView Node Manager.
Performance Measurement and Modeling Architecture
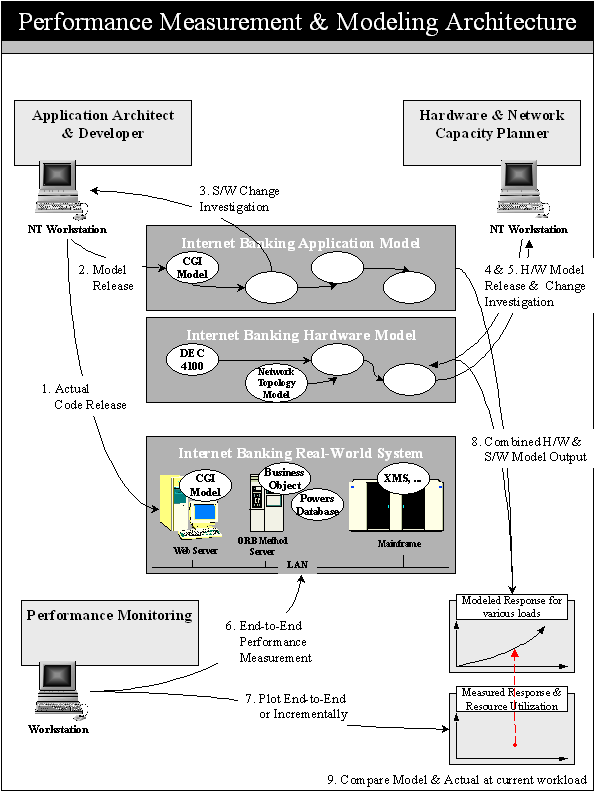
The following figure shows the processes and how the different performance activities complement one another.
1. Developers create and release the actual application code into production.
2. Simultaneously, these developers release their associated modeling modules for the application code.
3. Developers experiment with other modeling modules for possible code changes.
4. Capacity planners purchase or develop models for system components released to production.
5. Capacity planners experiment with models for hardware upgrades and future workloads.
6. Performance monitoring measures response times and resource utilization.
7. Performance monitoring reports end-to-end response times or across individual application components.
8. Performance modeling predicts response times at current workloads and many projected workloads.
9. Performance monitoring is used to calibrate the performance model curves at current workloads and validate the model.
Maintainability of Models as a Business Requirement
Our ability to keep our models up-to-date, given Wells Fargo's rapid development and the complexity of the production environment, is a valid concern that has been often expressed. This describes our investigations to quantify the magnitude of this maintenance effort and our approach to on-going maintenance of the model.
Hardware changes such as upgrades and additions to server platforms, routers, and networks are frequent within the Wells Internet Banking system. We need to account for this increased availability of hardware capacity in our model. Hardware availability can decrease as well. In addition to physically removing or shutting down server platforms, servers can be taken out of play by modifying a number of configuration files that acting together, determines the ultimate routing of Internet Banking transactions. It initially appeared that we needed to continuously "poll" the separate groups that are responsible for these changes in the different functional areas.
As we became more familiar with the production change reporting systems at Wells, we became more comfortable with our ability to know when these changes occur. We have access to the reporting tools and are included on distribution lists for automatic email notification of changes. Ultimately, systems integration personnel and capacity planners may be the logical owners to update the hardware models containing these configuration details, especially since the production change reporting is one of their current responsibilities.
ClearCase provides us with the tools to know what in the source code base has been changed from an older version to the current one. We experimented with using either the UNIX diff or the ClearCase cleardiff command on different versions of the same source code files to output the results to a file for comparison. Using simple shell scripts, we believe that we can automate the task of building comparisons of a hundred different files. We will then scan the comparison files looking for changes that are significant from a modeling perspective.
The magnitude of the task becomes more manageable if one considers that we are modeling just a small number of transactions (or threads of execution) through the entire application suite. The modeling effort principally encompasses predicting response times for key transactions such as sign-on, which are the most time consuming for the customer. Background load factors or coefficients are applied to all of the hosts and networks to account for all of the other normal computational activities in the enterprise. For capacity planning, potential hardware configuration upgrades are modeled with increasing workloads while constraining customer response times within acceptable limits.
Network Topology Characterization
We characterized the topology of Wells WAN and LAN networks from spreadsheets provided by the networking groups. Here again, Wells has extensive Intranet resources for searching IP addresses and network device names and connectivity. Although learning to use these tools required an initial investment in time, they have proven to be quick and accurate for keeping the model up-to-date. The traceroute utility was used to validate correct routing as well.
The end-to-end Internet banking response times as reported by our model do not appear to be sensitive to reasonable ranges of message sizes within the Wells internal networks. If we decide to eliminate this variable, we can instrument the source code to measure message sizes at the point that CORBA or Tuxedo messages are performed in low-level libraries.
Application Logic Flow Characterization
Wells Fargo internally designs, develops, and maintains all of its own UNIX-based Internet Banking applications, building from Clearcase repositories and using the GNU C++ compiler. As modelers, we are given access to the development and testing environments, which makes our approach possible. A benefit to the development organizations in return is that we require a minimal amount of support in our activities to characterize and maintain models of their constantly changing applications.
The Wells Internet Banking application is built upon several enabling technologies for open systems including:
· Netscape Enterprise Web Server
· BEA ObjectBroker CORBA middleware
· BEA Tuxedo RPC's
· Informix database for logging in the middle-tier
Applying this same level of modeling detail to vendor-supplied products is not possible, nor does it provide the same potential return-on-investment as it does for applications under our immediate control. Performing "what-if" analysis on the internals of source code, which we can't change or even access, does not make sense.
For the Netscape Enterprise Web Server model, we started with the web sample application provided with Strategizer, and made a number of modifications. For all of the commercially available products, we like to work with the vendors and other companies using Strategizer to better characterize these applications.
Creating Model Behaviors
Our methodology proposes that developers participate in creating Strategizer component models of the application programs, for which they are currently responsible. A major milestone in determining the complete adoption of Strategizer modeling activities by the Wells developer community will depend, in part, on their acceptance of Strategizer's ADN simulation language. As of this writing, the jury is still out on them picking up this task. As expected, developers are somewhat resistant to developing in other than their primary programming language. The authors appreciate the value added by the ADN language. For a modeling specialist, it's a perfectly reasonable to exclusively use a simpler language tailored to simulation tasks to get results fast. However, our methodology specifically decrees that developers not be "molded" into modeling specialists. Instead, the methodology guides them in writing modeling components that precisely reflect the business logic implemented in their principle language, in this case GNU C++.
When we describe the methodology based on analysis of source code, customers typically ask if the ADN-based modeling components could be automatically generated from the C++ source code base. The development of sophisticated cross-language compiler technology is clearly beyond our project scope. To lessen concerns over another language, we stress that, for C++-proficient developers, the task of learning ADN is comparable to learning a version of the BASIC language and is a manageable undertaking.
As a minimum, there seems to be agreement at Wells that the tasks of building and periodically updating ADN-based modeling components from source code can be precisely defined and scoped and therefore easily and economically out-sourced as an alternative. Again, the goal of the methodology is to reduce the degree of expert knowledge in building these application models through the use of procedures and "wizard-like" tools.
In writing behaviors for the model in ADN, we chose to use variable names, branching conditions and other code constructs, which closely paralleled those found in the actual source code. We used indenting of ADN statements in Strategizer behavior editing to indicate the function-calling hierarchy in the actual application source code instead of the block structure in the ADN code. Also, we "overloaded" the normal function of the ADN C++-style ( // ) commenting on many lines in the behaviors as well. Some of the comments contained identifiers or variables for function execution times as previously measured using the Quantify application profiler (discussed below). Quantify pairs these same function identifier names with the functions' execution times when it creates two separate output files. One Quantify output file contains execution times for just the function calls. Another Quantify output file contains the execution times for the functions added to the times for all of the descendent function calls of those functions. As an example of our use of ADN comments, a tag such as // F: Customer::Customer() was used if just the execution time to call a Customer object constructor function was desired. A tag such as // FD: Customer::Customer() was used if the execution times for the Customer object constructor function and all of the descendent functions that it called were desired.
Running the model from Strategizer's GUI produced the ASCII <model>.adn file, which could be parsed to find the F: and FD: comment tags with identifers for the function execution times. For this, we wrote a Perl script, which also parsed the Quantify files containing the execution times associated with those same identifier names. As output, the Perl script created another Strategizer Include file containing Constant assignments equal to the sum of execution times for a given block of F: and FD: identifiers in a Strategizer behavior. When we began the modeling, we used, for the most part, Quantify execution times of the FD: (function + descendent) type. Later, as we added more application depth to the model, which we learned from examining lower level function definitions, we replaced the top FD: tag with its F: tag counterpart and added more tags for the lower level functions that we modeled.
Our objective is to automate the task of entering the large number of execution times. Whenever we have to re-profiling the many Internet Banking programs with Quantify because of coding changes or ports to other platforms, it's a simple matter to re-run the Perl script once afterwards to update the execution times in the Strategizer Include file that the Perl script generates. With fifty or more execution times in the model, this saves a lot of time and typing mistakes.
The authors concede that the ADN programming conventions described above make the Strategizer behavior code more difficult to read for the uninitiated. However, our primary goal is to make the ADN behaviors easier for developers of the application programs to read, validate, update execution parameters and hopefully take ownership. Since the developers are already users of Quantify in their test environment we feel that application profiling is actually an easier process for getting execution times as compared to setting up a benchmarking environment, measuring response times and inferring execution times.
At first glance, it's natural to come to the conclusion that manually "translating" a large program from C++ to ADN is the ultimate example of over-modeling. We avoided this pitfall by keeping in mind that we were only interested in a few threads of execution for the model. This discipline greatly reduced the maze of potential branching of any robust system language not to mention the specific indirect from C++ constructors and overloaded method calls and the like. Object-oriented features in the ADN language would have helped to make the simulation code look more like the actual C++ code. However, ADN variable names with underscores instead of "." and "->" for C++ object member references as well as appropriate thread storage string identifiers that we selected were recognizable enough as their C++ counterparts.
Documenting the Application Model
We started our translation to simulation code by examining the flow of the application's C++ source code by following the function calling sequence into functions that appeared to contain significant modeling events. For our first pass, we wrote a narrative for what the application did and the sequence in which it called its functions, did I/O, or spawned other processes. These high-level documents, published on the Wells intranet, proved very useful to other performance analysts in our group for interpreting performance logging data. In some cases we provided hypertext links from function calls described in our narrative to the appearance of the function names in tracing logs generated by actually running the application with debugging turned on. This was done to make it easier for others to validate the accuracy of our documentation.
From these documents we wrote the ADN behavior code for just the threads of execution that we wanted to model - the transactions with high levels of visibility within the bank. Strategizer's Documentation Generator facility, which creates excellent HTML-formatted documentation of Strategizer behaviors, was a highly valued addition to our Wells intranet documentation capabilities. From our high-level application narrative Web pages, we created hypertext links from application function names described in the narrative to the HTML tags for associated model behaviors that were created by Strategizer's Document Generator.
Experiences Writing and Running Detailed Strategizer Behaviors
Strategizer's ADN language provides many discrete event simulation statements to directly model the UNIX mechanisms used in the Internet banking applications. ADN proved to be robust enough for the translation from actual production source code. ADN thread storage proved invaluable in implementing C++ naming conventions within Wells source code. UNIX select IO calls with timeouts are used extensively and we needed to model them accurately. In most cases, the ADN Receive statement itself was used for the select function IO blocking. An extra Receive parameter was sometimes used to indicate source file descriptor information for the select call. ADN messageSchedule statements were used with the Receive statements to model the UNIX select timeouts. However, one particularly difficult modeling task was encountered where a master process blocked on a select function call until a socket message was received. The complication arose because the master process then used a UNIX kill statement to signal one of a pool of worker processes whose signal handlers did the actual read from one of the file descriptors contained in the read mask of the select function.
Having this amount of legitimate, modeling-significant application detail to model, we were initially concerned that excessive run time for our large model would limit our ability to characterize the application logic in sufficient detail as our understanding grew. We devised a strategy where major detailed pieces of the model could be replaced by a single ADN Delay statement using configuration parameters and multiple Include files containing behaviors. Whenever we planned to focus the statistics reporting for a run on a particular section of the model, we would include its very detailed component model. However, integration and compatibility of the gross and fine-grained versions of modeling components became difficult and we finally merged all of the detailed components into one large model. Fortunately, run time for the large model has not been a problem for us. Although without confidence intervals supported by Strategizer, we are still uncertain as to how long to run the model. With our large model, startup time is slow during model testing and debugging. Of course, when we run the model in batch mode using scripts this is not an important issue.
Priorities for Characterizing System Resource Consumption
Based on our analysis of the Wells Internet Banking application architecture, we determined that we should initially focus on accurately characterizing CPU utilization. A CPU-usage model would immediately provide important performance insights to current performance problems and was the logical place to start modeling. A lot of attention has gone into characterizing CPU execution times for particular transactions, most notably the customer sign-on transaction for Internet Banking.
As of this writing, we have an accurate network topology model, accounting for all of the platforms, routers, LANs, WANs, and other hardware components touched by the Internet banking transactions that we've modeled. The task of using identified sources of utilization of other system resources (disk, memory, etc.) and allocating them to application transactions is under way and not complete.
From a disk utilization perspective, the Internet banking application places very little demands on the disks in the firewall, Web front-end and even BOS method server area. Proxy servers in the firewall read the same configuration file from disk each time they start. This is also true of the CGI processes and session-state processes residing on the Internet banking web server platforms. A limited set of HTML template files is also read repeatedly for dynamic generation of HTML reply pages. These files should be accessible in file system buffer cache through logical reads. An exception to this rule is writing to disk of dynamically generated HTML pages for redirects. Redirects to result pages generated for URL requests are used in many cases so the banking customers do not backup to previously completed and submitted forms and inadvertently submit them again, thereby accidentally duplicating the banking transactions. Redirects result in an extra trip to the Web server for URL requests and are important design feature to be modeled. Disks are not written to extensively except on specific BOS method server platforms, which are dedicated to logging BEV (Business Event) and MEV (Method Event) performance data. However, Wells middleware designers stressed that these are asynchronous writes and they are confident that they do not constitute a bottleneck.
Memory consumption is more of a consideration and is higher on the list of remaining areas to be modeled. In the interest of application security and application reliability, Wells currently achieves application concurrency through multiply spawned single-threaded processes for the proxy servers and the session-state processes. Hundreds of processes can be running simultaneously and competing for memory on each of the platforms in the production environment, although they do share text.
Application Execution Time Characterization
In the appendix, we evaluate the various tools and sources of CPU execution times that were available to us. We decided that application profiling provides the best accuracy and is most conducive to our goals of integrating modeling into the development life-cycle processes. After some experimentation with several application-profiling tools, we standardized on using Quantify from Rational Software Corporation.
Quantify Application Profiling
As described in the Quantify User's Guide [2], Quantify uses Object code Insertion (OCI) technology to count the instructions that a program executes and to compute how many machine cycles it requires to execute those instructions. By counting cycles, Quantify offers to give accurate data at any scale and in one run of a program instrumented with Quantify libraries. Rational contrasts this to the need to create long runs or make numerous short runs to get meaningful data as with sampling-based profilers.
In some cases, we needed to rely on single runs. We saved considerable time by using the results from a single run using a test harness that required a lot of setup to get to the functions of interest. However, we could not blindly assume that all of the function execution times were free of elapsed time, and therefore repeatable. Depending on the type of code being profiled, Quantify measures execution times in machine instructions, elapsed (wall-clock) time or kernel time. For example, system calls are measured in elapsed time as default. If selected, Quantify converts all of these measurements to cycle counts.
There is a Quantify -measure-timed-calls option that controls how system calls are timed. By default, -measure-timed-calls=elasped-time. This measures the elapsed time of each call. The user can specify -measure-timed-calls=user+system to measure the change in user and system time recorded by the kernel for the process. Unlike elapsed-time, user+system measurements do not reflect any time that the program and the kernel wait for other processes before the system call could be completed. The measurements that Quantify reports match more closely those reported by /bin/time for the un-instrumented version of the program. It only reports the amount of work that the kernel does to service the program.
The -measure-timed-calls=user+system option proved helpful to us in the separation of execution times for two processes communicating over a UNIX named pipe. We were able to account for the kernel time for just a sign-on CGI process doing reads, while excluding the time while the CGI process was waiting on a load_balancer process on the other end of the pipe to execute. The load_balancer process forks children load_balancer processes that handle the socket requests from the signon.cgi processes. Quantify captures the children's execution times as well. A runtime Quantify environment variable (-record-child-process-data) was set to allow child data to be recorded.
Regardless of how the measurements were made, we were concerned about correctly matching the units of execution times that Quantify produces to the units of execution times that Strategizer accepts.
Strategizer's Execute Dialog Box allows the modeler to enter CPU execution times in a variety of units (instructions, transactions, SPEC numbers, transactions, seconds, etc.). Following our instructor's modeling tip, we used units of machine instructions instead of seconds for CPU execution times. This eliminated the need to update times in seconds whenever we selected new hardware platforms and processor speeds from Strategizer's hardware configuration dialog windows.
Quantify allows the selection of machine cycles, regardless of the methods that it uses to arrive at its profiling results, which can be varied. It converts from instructions to machine cycles using its knowledge of the machine type and clock rate (MHz) for the machine on which the Quantify'd program was built. The following statements from a Quantify README file on a SunOS machine describe the differences between MIPS and MHz processor rating:
Quantify 's
Superscalar processor support is improved.
Newer processor chips
from Sun and HP are sometimes able to execute more than one machine instruction
at once (more than one per clock cycle). This type of processor is called a
"superscalar" processor. Examples include the SuperSparc (used in the
SparcStation 10 and 20), the UltraSparc (used in some new Sun machines), and
most HPPA (7100, 7100lc, 7150, 7200). Each has different restrictions on which
machine instructions it can execute at the same time. For example, the HP7100
can only issue one integer and one floating point instruction together.
Quantify now models each of these processors at instrumentation time to more accurately compute the time spent running your code.
The easiest way that Quantify cycle counts can be directly
input into Strategizer's Execute Application
"Instructions" CPU <cpu_value> statements is to change
the model's MIPS rating to reflect its MHz rating for a server platform
component, which Strategizer allows through its Processor Performance Table
Dialog.
Quantify API
functions
In addition to its build and run time options, Quantify offers a variety of API function calls for further control of data-collection of modified programs. We added some of these API function calls to the load_balancer source code and re-compiled. Whereas the CGI processes were short-lived and therefore bounded in the amount of data collected, the load_balancer is a long-lived UNIX daemon. To limit the data collection for the load_balancer, we used Quantify API function calls that capture signals that we can send to start and stop saving of profiling data. We used another Quantify API function call to clear out the parent's execution times from the execution times of its child load_balancer to avoid double counting.
In a single circumstance, we found it necessary to modify the application source itself to get the Quantify'd executable to run correctly. An instrumented program takes much longer to execute, although this overhead for data collection is excluded from the measured execution times. We had to modify the load_balancer source code to increase the time that the parent load_balancer slept after it forked a child. The Quantify'd load_balancer child process needed the extra time to start and be ready to receive a signal that the parent would send.
Integrating with Source Code Revision Control
Parallel to the tasks of implementing methodologies for keeping application component models up-to-date are the tasks of implementing processes for keeping track of and assuring access to correct revisions of the models. As performance modelers, we need this considering the large number of permutations of hardware configurations and the volume of expected "what-if" modeling requests, complete with comparisons to previous model results. During our presentations, the Wells development community was pleased to hear that we had already investigated the feasibility of maintaining application component models in their existing Clearcase source code repository. This is the logical choice if they decide to participate in building and maintaining application-modeling components.
The ability of Strategizer to export and later import a complete model in XML provides a viable approach to maintaining individual behaviors or collections of behaviors in Clearcase. We've successfully completed prototype Perl scripts, which parse Strategizer XML files into smaller files, check them into and out of Clearcase, and re-merge them into one file for import into Strategizer.
Graphical Presentation of Modeling Results and Remote Modeling over the Web
Working with the voluminous modeling input parameters and
statistics that Strategizer supports, we wanted to provide meaningful data
visualization of modeling results on the Wells intranet to help educate our
broader audience and develop interest in modeling. We considered several
approaches to allow remote modeling and presentation of Strategizer modeling
results in a meaningful way on the Web. Currently, we're experimenting with
Java-based applets and applications, which we continue to tailor to meet our
specific needs.
Browser User's Overall Experience
We propose to justify and measure the effectiveness of a Web-based modeling and modeling-results presentation tool by how well it:
1. Educates the user on what modeling can do for them, and
2. Motivates them to do or request modeling for their situations.
Effective education would show that through the activity of running the model (modifying variables and presenting changing performance results), users can better understand the performance aspects of complex distributed computing systems and thereby gain the ability to optimize its performance.
The problem with "raw" modeling results is that tables of numbers do not easily convey physical processes. Individual static line or bar charts for each modeling run are better, though comparison of many different graphs is cumbersome. A dynamic presentation, which invites the user's interaction, is preferable. Take for example the "flying-tour" visualizations of Martian terrain, computer-generated from thousands of radar-mapping data sets. The user can turn "knobs" to change their positions and viewing perspectives and virtually fly over Mars.
Likewise, a visualization tool that "flies"
through multiple runs of modeling data would invite interaction as well. Once
casual browser users understand simple systems through the view of a model,
they will be motivated to ask for changes to simple models to better reflect
their applications and systems.
Details of a Browser User's Interactions and Tool Operation
We're currently developing a Java applet and application that creates 2D line graphs of modeling results and ultimately will remotely run simulations on an NT server for browser users.
For browser users requesting an HTML page for a simple model advertised among a list of previously built models, an applet would be downloaded with the requested page. On download, the applet could have pre-loaded modeling data sets collected from previous runs of the model by other browser users before them. (Even in the case of simple systems, models would have multiple variables, each with several values.) This saved data could be viewed through the applet without remotely running the model. If the user-selected settings are all for previously modeled data, the applet would simply show the results as line graphs, e. g. Response Times vs. Increasing Workloads. Several curves could be super-imposed on one graph.
In other cases, the browser user could trigger Strategizer to run remotely. If the user-selected settings contain values, which have not been modeled, the applet would ask the browser user if he/she would like to run the model immediately for those new settings. If the user answers affirmatively and decides to wait for the results, the applet would signal a Strategizer server on the NT server to run the new model and give back the results, at which time the applet would present the graphs. The Strategizer server would then add the new data set to its collection for that model.
Over time for a specific model, more and more permutations
of the model would build up and future browser users would have to wait less
time for new simulations to be done. Of course, if the capability is added to
this tool allowing browser users to make major changes to the model (not just
variable settings, but network topology changes, for example), an entirely new
model would be constructed and the collection of modeling permutations would
have to start from scratch. To limit the scope of this tool (short of a
distributed version of Strategizer), those users would instead be encouraged to
get a private license of Strategizer for their own NT machines.
Look-and-Feel of the Modeling Presentation User Interface
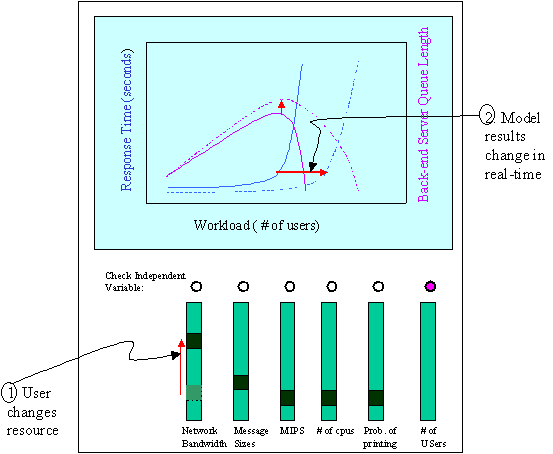
Our Java applet has a draw area where line graphs of performance curves are displayed. Multiple curves per display can be selected. Initially, we proposed slider widgets that would allow the applet user to increase or decrease modeling parameters and interactively see changes in the performance curves. For example, a network-bandwidth "knob" could be increased and the "knee" in the performance curve would be pushed-out, but only to a certain point. Then a CPU MIPS "knob" could be increased to further flatten the curve. This interactive experience would show users how bottlenecks can move around (from network, to cpu, to disk, etc.). As conceptually presented, the applet had a separate slider widget for each modeling parameter (See figure below). However, real-estate restrictions on the applet's GUI force us to use either scrollable panels of slider widgets or mode-sensitivity mouse "clicks/shift-clicks" for increasing/decreasing values.
For a fully populated model (i. e., all permutations of modeling input parameters have been previously run by previous browser users) there would be no interruption in the "flying" experience and no messaging between the client-side applet and a server-side serverlet that provides additional data. Where there are gaps, a knob would turn red, for example, to indicate to the user that data is missing and the display would not be updated for this parameter's value. A button labeled "Run Model" would be available to the user to remotely run Strategizer for that data set and transparently download the new results to the applet so that the display could be updated for that modeling scenario.
At its conceptual stage, the applet User Interface looked something like the figure below. (The scenario displayed could indicate that increased network bandwidth allows more messages to get to a middle-tier server and on to a back-end server. Back-end queue length peaks with more work getting through. However, after a point the middle-tier server saturates and starts to thrash with too many processes. The Back-end queue length falls because less work gets through from the middle-tier.) Currently, our charting application uses a greater variety of Java widgets and more graphing options.
Modeling Results
As stated before, our initial modeling objectives have focussed our attention on proving the feasibility of integrating modeling activities into both Wells existing performance analysis and application development processes. We have adhered to expert advice to avoid "playing with models".[1] Wells personnel, who are inherently technically knowledgeable, tend to accept our agreed upon deliverable, that is, a clearly defined modeling methodology, feasibility studies of its implementation components and technology transfer of performance modeling techniques. Where specifically asked to make predictions of previously experienced production problem, we've responded, and with favorable results. One prediction involved Internet Banking traffic across the Wells firewalls.
Particularly for the proxy processes in the firewall area, the CPU utilization cost of starting new processes on a per-transaction basis was a point of sensitivity for the model. This became most evident when the number of GIF images per HTML page was increased as an independent model input variable. Beyond the Wells firewall DMZ where the Wells Home Page Web servers are located, all HTTP requests must be secured with SSL by specifying the https:// URL prefix. Therefore, files for embedded GIF images necessarily originate from the same Internet Banking web server platform within the Wells secured LAN networks. Each additional socket connection for GIF's across the firewall requires an additional proxy process to be started. At a critical number of GIF's per page, CPU utilization on proxy server platforms saturated, cutting off additional Internet Banking traffic to the back end. This condition was first experienced in production as a result of marketing requests for enhancements to web pages and later duplicated in the model. Armed with Strategizer's extensive collection of statistics, we were able to point to precise mechanisms, which would not be evident using benchmark or other actual measurement techniques.
Appendix: Performance Tool Evaluation and Selection
This appendix describes the background and additional details leading to our selection of tools for the modeling effort. In some cases, tools were already available at the start of the project. In other cases, we experimented with tools and later rejected them for various reasons.
SES/Strategizer Performance Modeling Tool
In a much earlier consulting project to assess the scalability of the Wells Fargo Internet Banking system, one of the authors built a discrete event simulation model using SES/Workbench. At the time, the SES/Strategizer modeling tool was just being introduced. Based on the author's familiarity with SES/Workbench and the availability and adaptability of an existing distributed-ORB model at the modeler's disposal, he elected to go with Workbench at that time. Subsequently, Wells Fargo purchased Strategizer for a particular project with one of its internal business customers. At this point, the selection of SES/Strategizer over SES/Workbench for IT modeling is, of course, obvious for IT professionals. Wells Fargo potential modelers and their internal business customers instantly are won over by Strategizer's Network Topology editor and its wealth of hardware models.
We also evaluated Strategizer's ancillary beta features offered with the last two releases of the product.
Experiment Manager integrates automation of modeling runs based on a user's specified permutations of input parameters. Likewise, SES merging scripts and Visual Basic macro's allow charting of statistics over varying input parameters and multiple runs of a model. We look forward to the continued enhancement and availability of these Strategizer features. However, for the present we've elected instead to go with custom Perl scripts and Java coding, as described elsewhere in this paper. Current limitations precluding the use of these Strategizer features are the following:
· Experiment Manager requires that input parameters be entered in the Model Overview window. It does not recognize input parameters read from Strategizer Include files. As discussed in the section on incorporating Quantify profiler results, we compute the values of input parameter externally to Strategizer and assign them to Constants and Variables in a Strategizer Include file. We want to run sensitivity analysis on these execution time parameters and would like to run our automation scripts to handle these input parameters as well.
· Strategizer charting macros allow the user to select a subset of runs as its range of independent x-axis values to be plotted, either by manually deleting columns from its data table or by excluding runs during the merging step. The user must manually examine the values of input parameters for the runs to know which runs to exclude. We prefer that the charting tool do a comparison to user specified input parameter values to select a subset of runs, which adhere to those user selections, for plotting. Also, we would like at most a single mouse-click to navigate among the selection of statistics available for charting. This is described above under the topic of Graphical Presentation of Modeling Results.
We experimented briefly with the Strategizer interface to HP's Node Manager product (part of HP's OpenView Network Management product.) However, the version of Strategizer we were using at the time required that Open View be run under Windows NT, a platform for which we are not licensed. Also, networking auto-discovery management tools invariably require some manual assistance, which prohibits us from divorcing ourselves from other sources of network data.
Application Performance Logging and BEST/1 System CPU Utilization
In the previous Internet Banking-modeling project, execution times for application code path lengths were roughly estimated from an hour's worth of performance data from two sources:
· Source code instrumentation providing wall-clock response times and sample counts of methods call functions served by Business Object Server processes.
· System CPU utilization for Business Object Server processes as measured by BEST/1 performance monitoring.
The disadvantages of using these sources of performance data were:
· Difficulty of separating out networking and remote processing - Application logged wall-clock time per BOS method call could not be used by itself. The BOS methods calls, in turn, make remote calls to the Systems of Record (SOR) processes on the mainframe. So, the application-logging wall-clock times are not true indicators of just CPU execution time on the BOS platform. They also include time for networking to and processing on the mainframes.
· Difficulty of allocating CPU utilization to specific method calls - Any of the BOS method servers services multiple types of method calls. However, BEST/1 CPU utilization does not report to the granularity of function calls. Using the hourly count of method calls from the logging helped us to allocate the portion of total hourly CPU utilization to individual method calls. However, further assumptions based on the ratio of minimum response times for each method call recorded over the hour were required, which could not be easily verified and left the modeler with a feeling of uncertainty.
· Non-procedural approach - Bottom-line, this was a very data analysis-intensive approach, which relied to a great extent on judgement and, therefore, did not lend itself to easy automation or capture as a repeatable methodology.
Business Event Application Performance Logging
On the Internet Banking Web server platforms, which also host the session-state processes with ORB method clients, an additional set of performance data was available. Business Event (BEV) response time and sample count data are used by performance analysts to track business transactions (such as get account summary, get payee list, transfer funds, etc.) and identify performance problems.
However, BEV logging was designed for bank auditing and other purposes. As a result, the naming of logging events is not indicative of all of the steps in the transactions, which affect performance. As a side benefit of the application source code review to determine the logic flow required for the models, modelers were able to help the analysts to better interpret the BEV data.
For the same reasons as for the MEV performance data mentioned above, the BEV response times could not be used directly as CPU execution times for the model.
However, the Business Event data is an excellent additional point of modeling validation. The most visible proof of the accuracy of our model is a match of response times for the actual test and modeled Internet Browser users. The Business Event data provides many finer-grained points for model validation, as does the MEV data.
Browser Response Time Testing
As an ongoing quality control testing activity, Wells Fargo measures the Internet Banking experience from the customer's perspective, that is, through the browser client software. A suite of PC's running the latest Netscape, MS Internet Explorer and other browser software is set up to run Internet banking transactions and record response times. Actual browser testing offers a good point of validation for the response times recorded by Strategizer for our client workloads. However, this measured data does not offer the complete end-to-end validation of the model because the test browser PC's are located in the Wells data centers, which are inside the firewalls. Hence, the test browsers do not experience delays attributed to the firewall proxy servers and routers or Internet Service Providers (ISP). ISP's account for large delays in comparison to those within Wells Internet Banking itself. However, ISP's are currently outside the scope of our modeling efforts.
Browser response times are measured as the time between the display of particular screens representing a completed customer transaction. HTTP redirects and/or refresh commands by the Web server cause multiple trips to the server for a single browser click and contribute to the recorded response time for a browser transaction. Refresh times are set differently depending on the type of browser detected by the Web server application. It is important that the model account for this degree of subtlety in the Browsers' interactions.
Rational Software's Quantify Application-Profiling Tool
Application profiling seemed to offer a number of advantages over the use of application wall-clock time logging and BEST/1 CPU utilization measurements.
Disadvantages of application profiling with Quantify were:
· Quantify is not available or planned on all vendor platforms in the chain of Wells Internet Banking servers. At the start of the modeling project, Wells exclusively used Compaq (Digital) Alpha servers for front-end Web processes. Fortunately, a Hewlett-Packard HP 9000 platform was available in the development environment and was already used for both Purify and Quantify source code testing. We made the assumption that the two UNIX operating systems were similar enough to use the Quantify/HP 9000 measurements. (The implications of this are discussed under the section of Quantify and Super-scalar architectures above.) This platform dependence will not be an issue for our future Internet banking modeling.
Other Application-Profiling Tools
We also experimented with two other application-profiling tools:
· GNU gprof - Although gprof ran on Compaq development platforms, its measurements exclusively use wall-clock time as opposed to machine instruction counting as with the other two profiler tools.
· Compaq hiprof and atom - Atom is the testing user interface and hiprof is the actual profiling tool. According to their user documentation, these Compaq tools use object code-instrumentation techniques as does Quantify. The compelling reason for pursuing these tools is that they ran on the same vendor platforms as were used in the actual production environment. Technical difficulties were never resolved with these tools. Problems were attributed to development's choice to use the GNU C++ compiler. Hiprof reportedly only worked with Compaq's C++ compiler.
Programming and Database Environments
Wells Fargo Enterprise Performance Measurement has ongoing performance data management projects for managing and reporting on the BEV and MEV performance data. Our modeling activities were fortunate to be able to draw upon Perl programming and Oracle database expertise from these projects. These specialists helped to implement Perl scripts to automate running of models as well as management and extraction of modeling results for modeling results charting.
References
2. Quantify User's Manaul, Rational Software
3. 3-Tier Client/Server At Work, Jeri Edwards, with Deborah DeVoe - John Wiley & Sons, Inc.